We manage the learning management of a number of business and often get requests that go beyond the scope of most packaged learning systems - including our own. One of our customers asked if we could count assess all test answers, survey answers, and emails (most importantly) for a Flesch Reading Ease  score. Measuring the quality of an individual's writing was an efficient means of scoring and measuring the improvement of a particular student over time. The idea was that it didn't matter where and how writing material found its way to faculty, incoming text would always be scored (in context).
score. Measuring the quality of an individual's writing was an efficient means of scoring and measuring the improvement of a particular student over time. The idea was that it didn't matter where and how writing material found its way to faculty, incoming text would always be scored (in context).
The Flesch Reading Ease formula was first developed in 1943 by Rudolf Flesch in his PhD dissertation, Marks of a Readable Style. The early works of Fletch have found their way into two formulas that are most often applied to assess general readability - the Reading Ease score and the The Flesch–Kincaid formula. The former algorithm returns a score from 0 to 100, with 0 equivalent to a college graduate and 100 equivalent to the 5th grade. The latter formula presents a score as a U.S. grade level, making it easier for teachers, parents, librarians, and others to judge the readability level of various books and texts.
The Flesch Reading Ease score is so ubiquitous that a number of U.S states requires that insurance policies be written with a score that equates to a 4th grade level, and publishers have adopted score-testing to increase their readership - generally aiming for a score of 50 or higher (in comparison to academic and scientific papers that most often score lower than 30).

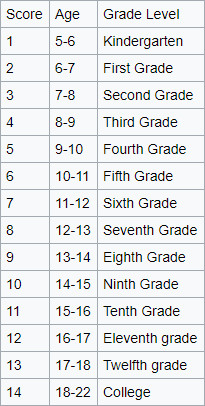
The Flesch–Kincaid score was developed in 1975 alongside the US Navy, and they later adopted the score to assess incoming cadets, internal forms, and text book readability. The score returns a U.S grade level approximation (adding a value of 5 to the result returns the approximate age of an individual in that grade).
No formula is entirely accurate... although the Flesch–Kincaid formula has withstood the test of time and is said to correlate with a score of 0.91 when measured again more traditional reading assessments.
Used in Marketing and Blogging
When you write marketing copy, sales copy, or an article on your website, you should generally aim for a Flesch Reading Ease score of around 60 so your efforts appeal to the largest readership. While there's a number of WordPress plugins that will make an attempt to score your article readability, few (if any) will return the result a graded results to your website's front-end... and none of them are overly accurate.
It's unknown if search engine algorithms apply any readability assessment to pages. However, from a holistic SEO point-of-view, it can't be ignored.
Flesch Reading Formulas
The Flesch Reading Ease and Flesch–Kincaid Grade Level algorithms are as follows:
Flesch Reading Ease
In the Flesch Reading-Ease Test (FRES). Higher scores indicate material that is easier to read; lower numbers mark passages that are more difficult to read. It's the Flesch formula that is applied to our example results below.
Flesch–Kincaid Grade Level
The "Flesch–Kincaid Grade Level Formula" presents a score as a U.S. grade level.
There are other readability formulas that are often used in addition to those above; they're reproduced below.
PHP Considerations
To assess the Flesch Reading Ease score, we require the total words, total sentences, and total syllables in a string... with the latter presenting the most significant hurdle.
First, to determine the number of sentences in a string of text, the following expression may be used:
We'll clean the text to retain only words and numbers (we're yet to receive a definitive answer on how numbers should be used).
PHP's str_word_count()  function can be used to return an array of words. We use this array to count the number of words in a string, and then we iterate over all the values to determine the number of syllables in each.
function can be used to return an array of words. We use this array to count the number of words in a string, and then we iterate over all the values to determine the number of syllables in each.
To determine the number of syllables in a word is tricky. After trying a few PHP functions (none of which we could rely upon), we landed upon Text-Statistics  - a library hosted on Github. The library is good but, not unlike some of the functions we wrote ourselves, wouldn't come close to returning the required accuracy. The syllable count is extremely important because of the significant impact it might have upon the Flesch score when erroneous data is returned. We determined that the only way of efficiently ensuring accurate results was to maintain a database of words and their syllable count.
- a library hosted on Github. The library is good but, not unlike some of the functions we wrote ourselves, wouldn't come close to returning the required accuracy. The syllable count is extremely important because of the significant impact it might have upon the Flesch score when erroneous data is returned. We determined that the only way of efficiently ensuring accurate results was to maintain a database of words and their syllable count.
An API was the logical means of returning data to our clients that required it (this also makes maintaining an accurate dictionary a crowd-sourced effort).
We accept three requests; one that requires a basic word => count be returned, another with the syllable count, and a last one with other data (such as vowel and consonant count for each word). Default usage returns only the count. The array that returns the word and syllables looks a little like this:
If a word isn't found in our database, it is recorded for manual inclusion. It's only if a word isn't included in our dictionary that we'll apply a less-efficient means of determining the syllable count via a PHP algorithm.
API Endpoint: http://api.beliefmedia.com/readability/api.php. A POST request expects at least 2 parameters: apikey and message.
A sample function to submit post is as follows:
A function to return the array should be used to check for errors and valid JSON (omitted for the sake of the example).
The code of 200 simply means we process your request. A returned error of anything other than 200 means that no result is returned. The final result should be cached so values might be retrieved (and displayed) if required.
WordPress Function
Note: Because of the nuisance processing overhead associated with each request, we only make the API available to our clients.
The WordPress function will cache the result for just 5 minutes if saving a draft. Since the syllable dictionary will evolve over time, a post when published will cache the result for only 60 days (a fresh request is made periodically to return a more reliable score over time).
Copy and paste the WordPress function into your theme's functions.php file or, if you sensibly have one installed, your custom functions plugin.
Note: The beliefmedia_post_readability function is also required.
Usage
To return a flesch score for an entire post, use the shortcode of [fleschscore].
[flesch]This page is a really bad example because of the technical nature of the subject and, as such, returns a Flesch score of around 45. The problem with making attempts to score articles like this one (and lots of other tutorial-type posts) is that they're far from the typical texts intended to be scrutinized and scored - they're just far too removed from the typical text required to assess literacy (as determined by the simple formula). For this reason, you might consider scoring individual paragraphs by wrapping your text in opening and closing [flesch] tags. For the sake of the example we simply tack the result on the end of a paragraph as follows (in real world use you'll record the result and use it elsewhere): [/flesch]
The sample function to return what we've described above is as follows:
Our plugin provides an option to include a score for every post in your WP publish META box.
Considerations
- If you're after a vowel and/or consonant count, the following expression will do the job (there's probably more efficient ways of doing so).
1<?php2preg_match_all('/[aeiou]/i', $string, $vowels);3456
- Processing posts with code is problematic because the readability algorithm assesses the complexity of a sentence without discriminating against any of the text. For that reason we remove anything between
preandcodetags, and HTML. How the inclusion of numbers is used for the purpose of the assessment seems to vary from one organisation to another. Consider the three-syllable word "29th" - do we include this in our count? Should titles and headings be considered a sentence? The existing web tools seemingly make their own interpretations meaning that scoring on one tool rarely matches that of another. - We include numbers in the word count and generally exclude them from the syllable count. To find the balance we were happy with we turned to Microsoft Office and compared our count to theirs when measured against a full copy of Harry Potter (we matched the novel assessment with 98.4% accuracy). This comparison required that we included a large number of very bizarre words to our dictionary! For comparison, the premium service Readable
 returns 84 percent accuracy.
returns 84 percent accuracy.
- As noted above, Microsoft Office will return a Flesch and other scores. Navigate to
File -> Options -> Proofingand tick the box that says "Show Readability Statistics". Select "Spelling & Grammar" when writing to see the results.

- We make attempts to remove anything other than the necessary text required to return a score. It might be prudent to exclude text, code, or anything else you don't want assessed.
- For those interested, the math formulas on this page were generated with Mathjax.
- Our tool scores word documents, PDF documents, and bulk uploads (in addition to numerous other features). It's likely we'll turn it into a report-to-email service after our dictionary is more comprehensive (at the time of writing it's at 75,000 words).
- We won't stop working on improving our algorithms!
- Click the "Show More Readability Formulas" blind below to show additional readability options. Most are returned in our API data.
Download
Clients should be logged in to download this plugin.
■ ■ ■
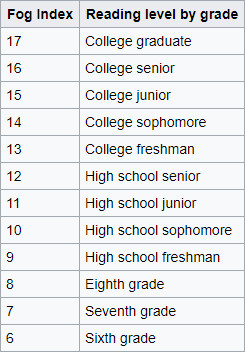
 education a person needs to understand the text on the first reading. A fog index of 12 requires the reading level of a U.S. high school senior (around 18 years old). The test was developed by Robert Gunning, an American businessman, in 1952.
education a person needs to understand the text on the first reading. A fog index of 12 requires the reading level of a U.S. high school senior (around 18 years old). The test was developed by Robert Gunning, an American businessman, in 1952.








{kind=link}
{kind=link}