We recently conducted an experiment in Artificial Intelligence that required highly accurate speech-to-text and text-to-speech functionality. In short, we assigned mortgage broker tasks to an AI and had the system carry a loan (with supervision) from a website-based AI-enquiry through to 'settlement'. The results give us a very clear indication of how the industry might evolve in the very short term, and it highlighted the efforts and technology that businesses might need to employ in order to effectively compete in a changing market. Every stage of the broker stack and workflow was faster and more efficient than human interaction - from assessing suitability for certain products, assessing risk, handling documents, through to 'CRM management'. A video discussion is forthcoming where we discuss the implications of this experiment. Until now, we've seen AI and tools such as ChatGPT used to perform functions - not tasks... and it's the understanding of a workflow, and the AI's ability to automate the process with virtually no human interaction that'll have very pressing and profound implications on those organisations that fail to implement appropriate changes into their operation.
In all cases, those files carried by an AI had a higher customer satisfaction rating when compared to those handled by a broker or processer, and in all cases AI was at least was twice as fast. The implications of AI systems in the finance industry will fundamentally change the way we do business. All aggregation groups and individual brokers need to assess their position now. The rate at which various products are making their way into the marketplace is unprecedented in the technology space, and those that fail to recognise the need for change are essentially driving the Titanic.
Our text-to-speech (TTS) and speech-to-text (STT) modules were used to automate various types of communication for the process we've just described, and both these modules are now available to clients through website shortcode, an Elementor widget, and the API. This article provides a brief introduction to the STT and TTS modules.
Introduction
Text-to-speech (TTS) and speech-to-text (STT) functionality was required to give the AI a voice, and to accept human instructions from the broker. We connected the Ai to our VOIP system (meaning it was capable of making two-way phone calls), and we sent automated voice notifications via SMS and email. Rather than use an external system, we updated our own APIs in a way that was designed to be suitable for the our very specific needs. This API is now available to clients for general use.
The very first feature we'll introduce by way of the TTS system is an accessibility tool that will render your article audio at the top of each post on your website. It'a a basic application in terms of what the system is capable of, but that doesn't diminish the value of the new product. This feature will apply to articles you manufacture yourself, and articles sent to your website via the article distribution system. Discussed further shortly, some users may provide us with voice samples so we're able to emulate your own voice on your own website... otherwise a selection of default voices apply.
OpenAI: Interestingly, the open sourced backend STT feature (generating transcriptions from video or audio) is powered by OpenAI (the group behind ChatGPT), suggesting that they're ridiculously close to building speech recognition into their own tools. This is game-changing.
Partner Article Audio: Our partner article program has established itself as one of the most powerful partner tools in the industry, and it's supporting brokers with the fastest-growing partner networks. The accessibility audio will be made available in these articles, although it'll be a couple of weeks before we resolve the most effective method of including the feature.
As stated earlier, the APIs we're introducing are a small part of our future with AI, but they do give the Intelligence a voice and ears - essential when the systems play a part in the processing component of your operation.
Text to Speech (TTS) API
The TTS engine isn't fast, so all requests are queued (with managed clients processed ahead of standard subscribers). A POST request is made to the API, and a response is returned indicating that the text is queued for processing. Once complete, a webhook is sent to a defined URL with details and download link. The webhook optionally carries the encoded MP3/WAV data in the request.
There are currently two distinct TTS engines. One produces very human-like speech (often indistinguishable from an actual voice), and the second produces a slightly more synthetic voice. The latter is available to virtually all clients because it consumes very limited processing resources. The former model is part of our ongoing AI development and is limited to selected managed clients and limited modules.
For the purpose of demonstrating voices, we used the following short snippet of text:
A large number of voice options apply for both models.
General Model
The following are default voice samples provided by the synthesis library, although as with the advanced model, we can (and will) manufacture our own suite of voices. Default parent voices are apope, arctic, hifi, ljspeech, ailabs, and vctk, although there are dozens of child voices available from within these collections.
Example audio is as follows (each took just a few seconds to generate).
[bm_tts voice="ljspeech_low"] .. [/bm_tts]
[bm_tts voice="popey"] .. [/bm_tts]
[bm_tts voice="arctic"] .. [/bm_tts]
[bm_tts voice="hifi"] .. [/bm_tts]
Various inflections may be applied, and mood may be modified by way of various classifiers, such as amused, angry, disgusted, drunk, neutral, sleepy, surprised, and whisper. Voice usage is introduced in more detail in the more comprehensive API documentation.
Advanced Model
The advanced model is commercial grade in nature, and returns results that are comparable with high-priced systems. Until a dedicated server is assigned, the model has limited availability. A few samples are as follows:
[bm_tts voice="atkins" version="1"] .. [/bm_tts]
[bm_tts voice="dotrice" version="1"] .. [/bm_tts]
[bm_tts voice="random" version="1"] .. [/bm_tts]
[bm_tts voice="random" version="1"] .. [/bm_tts]
As detailed below, the advanced model will reproduce your own voice in a manner that is almost indistinguishable from an actual recording.
Note: It's likely we'll initially introduce the advanced model into the automated SMS modules. This will limit the character count and reduce the overhead associated with processing the data. This will enable personalised SMS messages (in your own voice) with a name after various types of subscriptions and trigger actions.
The advanced model includes a large number of options to alter tonal quality, inflections, mood, and other vocal attributes.
Making API Requests
To create an audio file from the API, you'll need a function to submit basic data to Yabber, with the only required field being your text. By default, the request will send to the basic engine with a version value of '2', while a value of '1' will request processing via the advanced model. A sample function is as follows:
Project ID: A project ID is a 32-character HEX string that identifies your project in Yabber. If not applied, a new project is created. To update any audio, include the project ID in your request (this is returned to you in the webhook).
You will either see an error, or a success response:
The text is queued in Yabber and is processed in turn. When complete, you will either receive an email notification, webhook notification, or no notification. When the created response is sent it will include a link to the audio file and a full suite of transcriptions made for the purpose of applying accessibility subtitles (the Speech-to-Text module is introduced in the next section). The response sent via webhook will look similar to the following:
Introduced shortly, if the request is made via WordPress via shortcode or Elementor, the voice files and transcriptions are automatically sent back to your website for use locally.
Providing Your Own Voice
To generate a voice modelled on your own, we require at least ten 10-second clips of your natural voice without excessive stuttering or vocal disfluencies (filler words such as 'umm' or 'aaaa'). You'll want to save the clips as a WAV file with floating point format and a 22,050 sample rate. You will want to avoid clips with background music, noise or reverb, and you shouldn't include speeches as they generally contain echos. In short, you'll want nice clean clips created specifically to train your own voice model. The idea source of data is actually reading a blog post from your website as this is where we'll initially use your model.
For all managed clients, we'll create a voice for you at no charge. For others, there will likely be a fee involved.
Suggested Usage: Some time back we introduced the value of introducing some nested funnel videos that address a funnel participant by name. In the beginning, we'd have a broker record a few hundred introductions before stitching that audio into a video. A personalised voice presents an opportunity to create these personalised videos with ease and in bulk. It'll be a little while before the functionality is built into Yabber, but it's not far off.
Speech to Text (STT) API
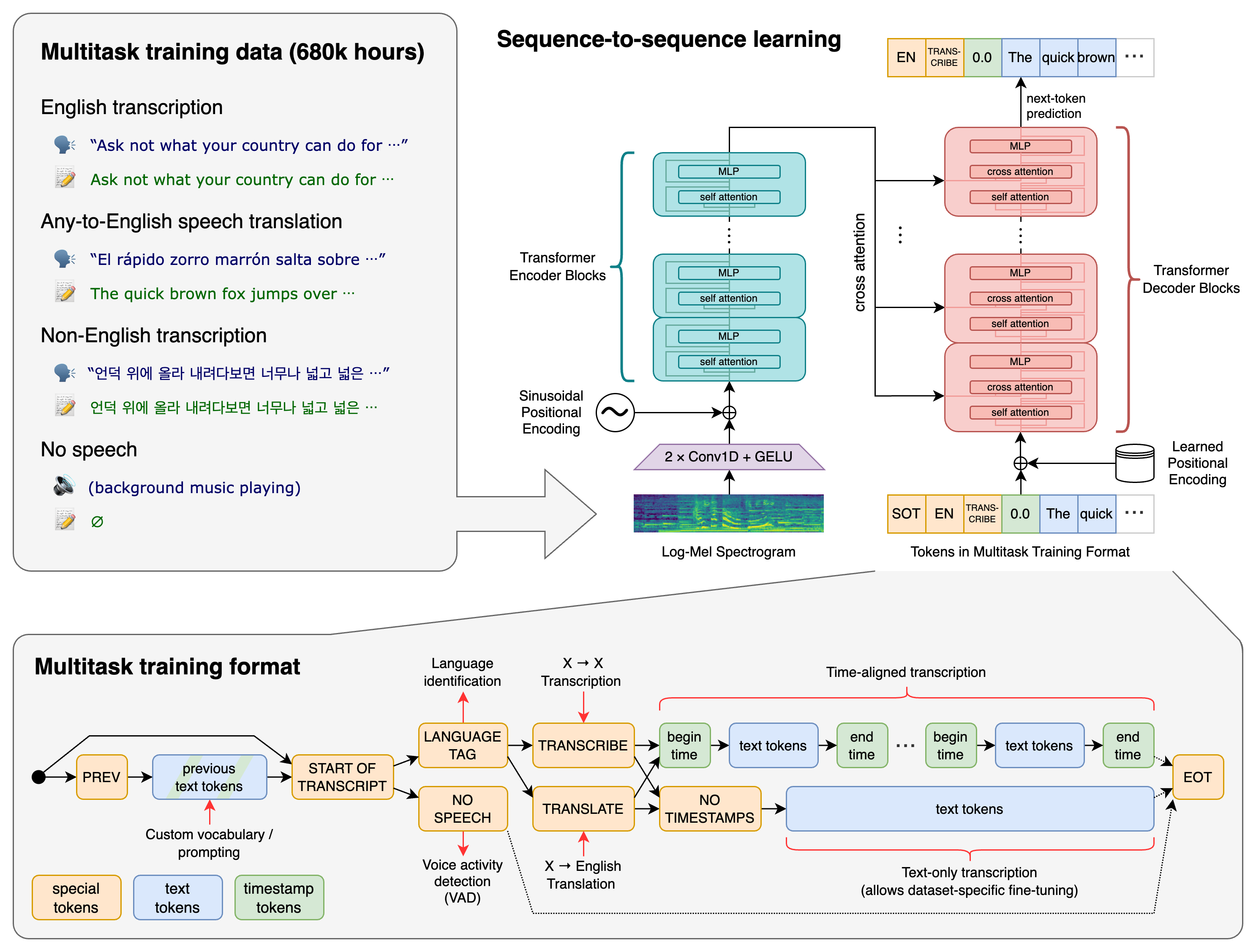
The STT API uses OpenAI's Whisper  installed locally on our server. Whisper is a general-purpose speech recognition model. It is trained on a dataset of over 680'000 hours of diverse audio, and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification. It is highly accurate, and almost always word-perfect.
installed locally on our server. Whisper is a general-purpose speech recognition model. It is trained on a dataset of over 680'000 hours of diverse audio, and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification. It is highly accurate, and almost always word-perfect.
The STT API works in a similar manner to the API. You submit an audio or video file to Yabber, and a basic success response is returned with an ETA for completion. The audio is queued and processed, and a json, srt, tsv, txt, and vtt file is created, with the SRT file the most widely used. When processing is complete, an optional webhook will be sent to a defined URL with links to download the various files. A complete transcription array is also included in the JSON response.
If using Yabber, and if the module is assigned to you, transcriptions are available in the STT module. All text is archived with keywords so you're able to assess your word count (useful for SEO) but also so you're able to conduct full text searches - extremely useful for recorded telephone calls and compliance (if integrated with your CRM, and if access was assigned to your account, transcriptions will be sent to your CRM as a note).
The TTS module will perform translations into a number of languages, and the languages are defined in the package sent to the API.
There are two primary methods used to transcribe audio: Yabber, and the API. Yabber is a simple point-and-click process, but the API requires a little technical knowledge. To use the API you'll need an API Key, and either CURL or a Requests library installed on your system. The following sample PHP function is the most basic implementation.
All fields are required or the API will throw an error. The audio extension is required for validation purposes and is discarded before processing (advanced usage will create another audio file on the basis of this argument). A webhook ID (sourced from Yabber) should be set in the body field if you wish to receive a webhook once processed. In the example above we have assumed a global BM_APIKEY was defined.
If an error is encountered you will receive a response with the message field noting the reason for the error:
A successful response will return some basic information. Note that if you provide a webhook and that hook is invalid, the webhook field will be empty and a response will be added to the message array with a key of 3. The estimated time for completion in seconds is noted by way of the scheduled value.
The webhook response includes the full transcription and links to individual transcription files. Note that the webhook system, and an example PHP script for processing the incoming data, is introduced in an article titled "Webhooks in Yabber". The response below is snipped for length, and certain fields were truncated with an ellipsis.
The response headers will include your API Key for validation purposes, and to ensure your endpoint is free from abuse.
Zapier: We've avoided created an application on Zapier, but it's likely we'll do so very soon. We're a short time away from releasing our own version of Zapier but focused almost entirely on the mortgage market. This integration was required primarily to support our free broker plugin, meaning that users of the free product will have additional automation options made available to them - including GPT AI integration
Yabber TTS and STT
STT and TTS functionality is integrated directly into Yabber. All requests are scheduled so it may take a few minutes before your data becomes available. A full record of all data is available in tables, and resulting renderings are available to download directly. Any request made via your website (and the associated data) is included in your creation log.
A feature we've used for years, and one that will be pushed as a global feature very shortly, is the automated transcriptions made via our VOIP systems. The transcriptions (and recordings) made from phone calls, conference calls, and notes, will be assigned to the relevant user for compliance purposes. All transcripts are fully searchable.
TTS Elementor Plugin and Shortcode
All audio examples on this page were created with an in-post shortcode. The audio is created by wrapping the text you'd like created into audio with the [bm_tts] opening and closing tags [/bm_tts]. All the options in the request function are available as shortcode attributes (such as voice="arctic").
Processing Time: Once an article is published, the text of 'Audio Pending' will be returned in place of audio. It can take a short time before the audio and STT subtitles are retuned back to your website. This is done to avoid processing multiple audio files for a single post.
The Elementor plugin is very much an early tool that should be used with the understanding that it may change shape before it makes its way into a Release Candidate. Until we receive the appropriate feedback from clients we aren't entirely sure what functionality will be required.

Pictured: Shown is the Elementor block used to create audio from text. You simply drag the textbox onto your page, enter the text, select a voice, and save. It will be a short time before the audio is returned back to your website. The inset shows the advanced options and the voice library. The webhook option allows you to send audio created within your website environment to external resources.
As best we can tell, our Elementor TTS Block is the only example of its kind.
Considerations
In Development
As stated, the STT an TTS modules are in active development. While the systems are reliable and generally work flawlessly, they shouldn't be relied upon for mission-critical applications. The exception to this is when assets are created in Yabber - it's the website and funnel components that'll be the focus of continued development.
Speech is an Integrated Feature
Over the next few months you'll see us drip-feed the functionality into other applications. Our VOIP integration, for example, has always transcribed call audio into a searchable archive for compliance purposes, although this functionality was integrated with Microsoft's commercial STT systems (so incurred additional charges), so we migrated that task to Yabber. In terms of broader AI applications, these transcribed conversations form the basis for contextual and GPT systems to gain an understanding of previous interactions.
As mentioned earlier, the creation of custom audio messages to be used with the SMS module (as an MMS Voicedrop) with your own voice is in trial and pending release. This feature will likely also encompass the email marketing module, and will also be added to the trigger system for standard workflow actions.
We're currently trialing various types of video functionality that will create an animated avatar to match created audio. It's a resource-hungry operation so it'll be a while before we make is available, but it is a feature we're working with. This will enable you to create full videos based on nothing other than text.
Subtitle Transcript Files
When audio is sent back to your website, a full suite of transcription files are also included. The HTML5 audio element doesn't support audio subtitles  by default, but the video element may be applied as an alternative... although this method is a little messy. When a custom video and audio container is applied we'll update the code to support the accessibility feature.
by default, but the video element may be applied as an alternative... although this method is a little messy. When a custom video and audio container is applied we'll update the code to support the accessibility feature.
Improve Media Conversions
Some time back we provided an article on how we improved upon video conversions by adding the name of a funnel participant into videos, but this was accomplished by literally recording multiple introductions. The advanced API now provides a facility where this same functionality can be achieved (automatically) in your own voice before being applied to videos. It's areas like this where we might see some early efforts return improved funnel results.
Accessibility - Your Articles as Audio
As noted earlier, the tool might be best served as an accessibility feature first and foremost, and it's this functionality that'll likely be served by default sooner rather than later. It's quite possible that the tool will also be modified to return multiple languages. In all cases, consider reading out your articles in full, or perhaps include article audio littered with supporting chatter in a podcast-like format. All these options will be built into Yabber.
Custom Audio Container
The audio containers used on this page (at the time of publishing) are the default HTML5 containers, so they may look different based on the browser you're using. We have a custom audio container and Elementor widget planned for next month.
Ethical Considerations
AI introduces the obligation to maintain ethical standards. We're now exposed to a world where video and audio can easily be manipulated to emulate any person with simple training data. The audio below isn't overly good, but it does demonstrate how Tom Hanks' voice can be reproduced in a manner that may be deceiving. The only voices we'll manufacture on your behalf are those of your own team.
[bm_tts voice="tom" version="1"] .. [/bm_tts]
We routinely see this tech being used to create voices from people such as Elon Musk to support Binary and crypto trading scams. It's a massive problem.
Commercial Solutions
Our solutions aren't nearly as capable as many of the commercial systems made available, with Microsoft's STT a clear standout. Adobe provide a number of products, including Adobe Podcast - just one of many tools you should consider for more advanced projects.
Conclusion
In terms of our AI ambitions, STT and TTS functionality are both very simple features, but the systems have provided our BeNet AI with a voice so it's able to interact with the real world.
With the introduction of open-sourced tools and accessible AI engines, technology reached an infection point last year that gave birth to an AI-uprising... and the development of these systems is exponential. Unless AI-based tools are introduced to your operation, the 'other' guy will process enquires faster, more efficiently, and with better customer outcomes.
Outside of our own client base, we've not seen a great deal of AI-based functionality introduced to the mortgage market, and this includes basic TTS and STT modules. We've not even seen accessibility features introduced to funnel assets, and this really does have to change. The industry is evolving in a way that's easier to identify when you're exposed to the technology, but most brokers are operating with a blissful unawareness of the mammoth changes that will potentially impact their existing business model.
Because of the continued development of this tool, you should follow our social channels for various updates and new features that might be made available.








{kind=link}
{kind=link}